Updates an "EffectData" object by
turning discrete values to factor (especially useful with the next option),
collapsing levels of categorical variables with many levels,
dropping empty bins,
dropping small bins,
dropping bins with missing name, or
sorting the variables by their importance, see
effect_importance()-
Except for sort_by, all arguments are vectorized, i.e., you can
pass a vector or list of the same length as object.
Arguments
- object
Object of class "EffectData".
- sort_by
By which statistic ("pd", "pred_mean", "y_mean", "resid_mean", "ale") should the results be sorted? The default is "no" (no sorting). Calculated after all other update steps, e.g., after collapsing or dropping rare levels.
- to_factor
Should discrete features be treated as factors? In combination with
collapse_m, this can be used to collapse rare values of discrete numeric features.- collapse_m
If a factor or character feature has more than
collapse_mlevels, rare levels are collapsed into a new level "other p". Standard deviations are collapsed via root of the weighted average variances. The default is 15. Set toInffor no collapsing.- collapse_by
How to determine "rare" levels in
collapse_m? Either "weight" (default) or "N". Only matters in situations with case weightsw.- drop_empty
Drop empty bins. Equivalent to
drop_below_n = 1. The default isFALSE.- drop_below_n
Drop bins with N below this value. Applied after collapsing. The default is 0.
- drop_below_weight
Drop bins with weight below this value. Applied after collapsing. The default is 0.
- na.rm
Should missing bin centers be dropped? Default is
FALSE.- ...
Currently not used.
Value
A modified object of class "EffectData".
See also
Examples
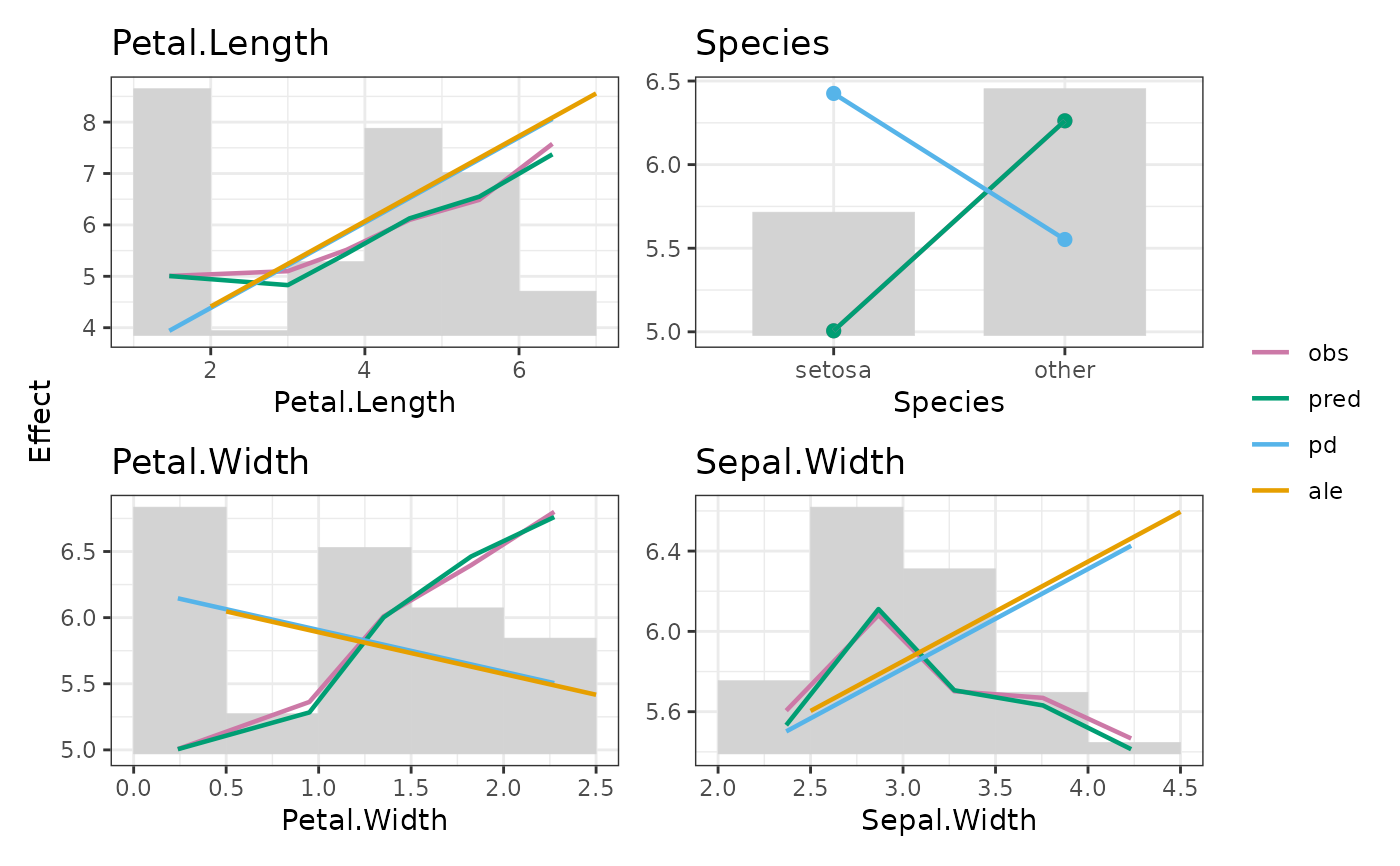
fit <- lm(Sepal.Length ~ ., data = iris)
xvars <- colnames(iris)[-1]
feature_effects(fit, v = xvars, data = iris, y = "Sepal.Length", breaks = 5) |>
update(sort = "pd", collapse_m = 2) |>
plot()