Calculates average observed response over the values of one or multiple
variables specified by X. This describes the statistical association between the
response y and potential model features.
average_observed(
X,
y,
w = NULL,
x_name = "x",
breaks = "Sturges",
right = TRUE,
discrete_m = 13L,
outlier_iqr = 2,
seed = NULL,
...
)Arguments
- X
A vector, matrix, or data.frame with features.
- y
A numeric vector representing observed response values.
- w
An optional numeric vector of weights. Having observations with non-positive weight is equivalent to excluding them.
- x_name
If
Xis a vector: what is the name of the variable? By default "x".- breaks
An integer, vector, or "Sturges" (the default) used to determine bin breaks of continuous features. Values outside the total bin range are placed in the outmost bins. To allow varying values of
breaksacross features,breakscan be a list of the same length asv, or a named list with breaks for certain variables.- right
Should bins be right-closed? The default is
TRUE. Vectorized overv. Only relevant for continuous features.- discrete_m
Numeric features with up to this number of unique values should not be binned but rather treated as discrete. The default is 13. Vectorized over
v.- outlier_iqr
If
breaksis an integer or "Sturges", the breaks of a continuous feature are calculated without taking into account feature values outside quartiles +-outlier_iqr* IQR (where <= 9997 values are used to calculate the quartiles). To let the breaks cover the full data range, setoutlier_iqrto 0 orInf. Vectorized overv.- seed
Optional integer random seed used for calculating breaks: The bin range is determined without values outside quartiles +- 2 IQR using a sample of <= 9997 observations to calculate quartiles.
- ...
Currently unused.
Value
A list (of class "EffectData") with a data.frame per feature having columns:
bin_mid: Bin mid points. In the plots, the bars are centered around these.bin_width: Absolute width of the bin. In the plots, these equal the bar widths.bin_mean: For continuous features, the (possibly weighted) average feature value within bin. For discrete features equivalent tobin_mid.N: The number of observations within bin.weight: The weight sum within bin. Whenw = NULL, equivalent toN.Different statistics, depending on the function call.
Use single bracket subsetting to select part of the output. Note that each data.frame contains an attribute "discrete" with the information whether the feature is discrete or continuous. This attribute might be lost when you manually modify the data.frames.
Details
The function is a convenience wrapper around feature_effects().
See also
Examples
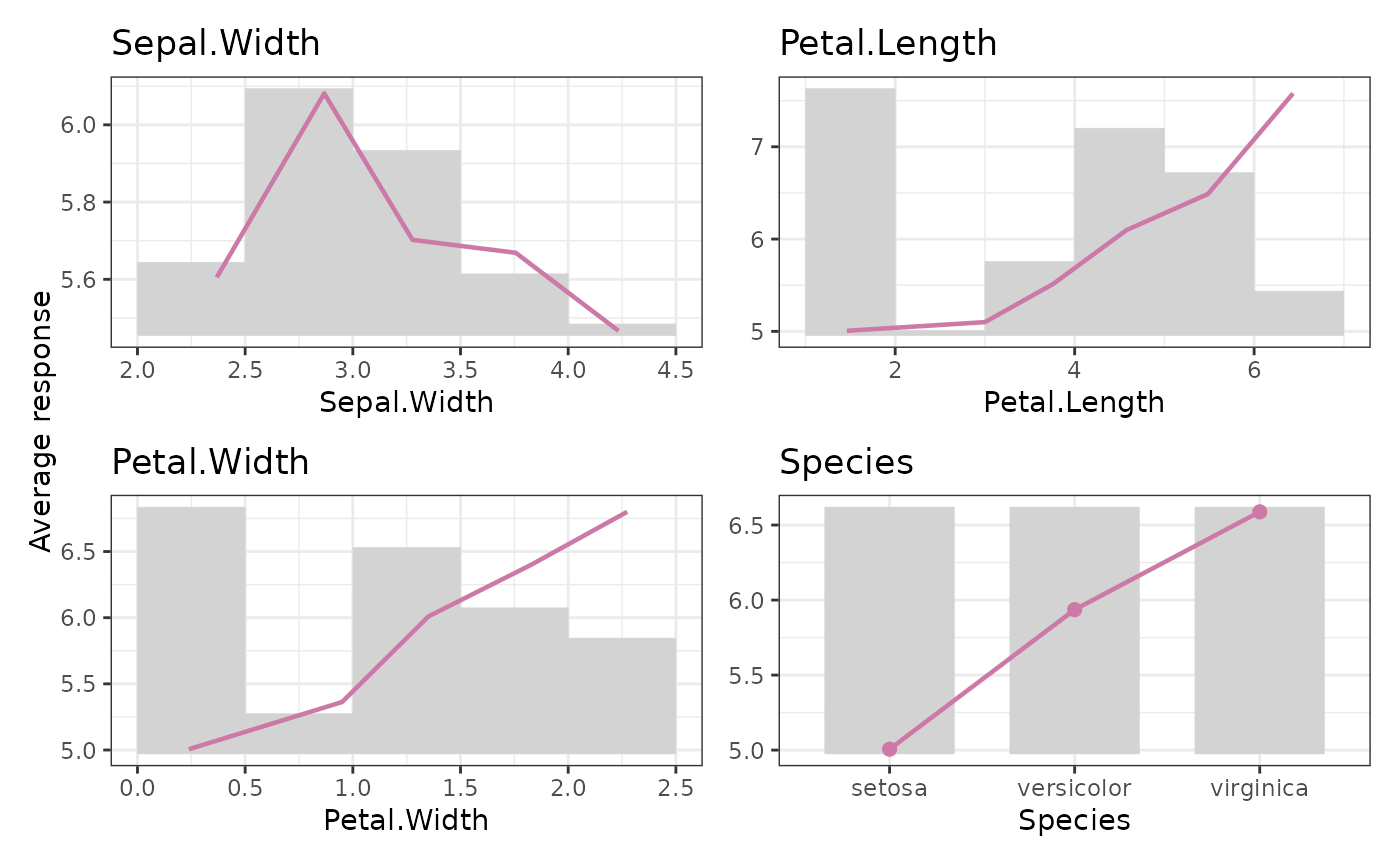
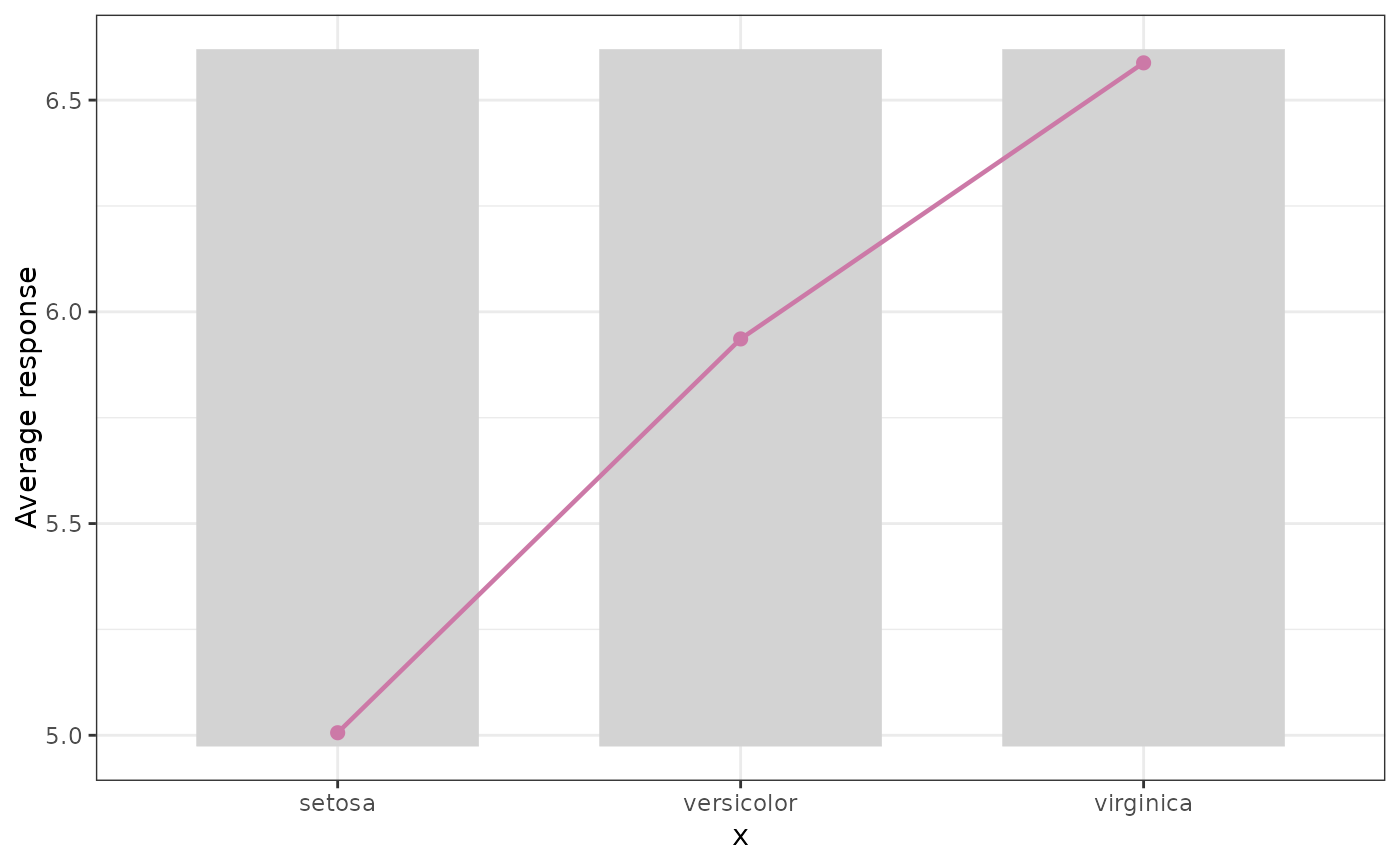
M <- average_observed(iris$Species, y = iris$Sepal.Length)
M
#> 'EffectData' object of length 1:
#>
#> bin_mid bin_width bin_mean N weight y_mean y_sd
#> 1 setosa 0.7 setosa 50 50 5.006 0.3524897
#> 2 versicolor 0.7 versicolor 50 50 5.936 0.5161711
#> 3 virginica 0.7 virginica 50 50 6.588 0.6358796
M |> plot()
 # Or multiple potential features X
average_observed(iris[2:5], y = iris[, 1], breaks = 5) |>
plot()
# Or multiple potential features X
average_observed(iris[2:5], y = iris[, 1], breaks = 5) |>
plot()